New Class of Accelerated, Efficient AI Systems Mark the Next Era of Super computing
Researchers worldwide will tackle grand challenges in science and industry with generative AI and HPC on systems packing the latest NVIDIA Hopper GPUs and NVIDIA Grace Hopper Superchips.
NVIDIA today unveiled at SC23 the next wave of technologies that will lift scientific and industrial research centers worldwide to new levels of performance and energy efficiency.
“NVIDIA hardware and software innovations are creating a new class of AI supercomputers,” said Ian Buck, vice president of the company’s high performance computing and hyperscale data center business, in a special address at the conference.
Some of the systems will pack memory-enhanced NVIDIA Hopper accelerators, others a new NVIDIA Grace Hopper systems architecture. All will use the expanded parallelism to run a full stack of accelerated software for generative AI, HPC and hybrid quantum computing.
Buck described the new NVIDIA HGX H200 as “the world’s leading AI computing platform.”

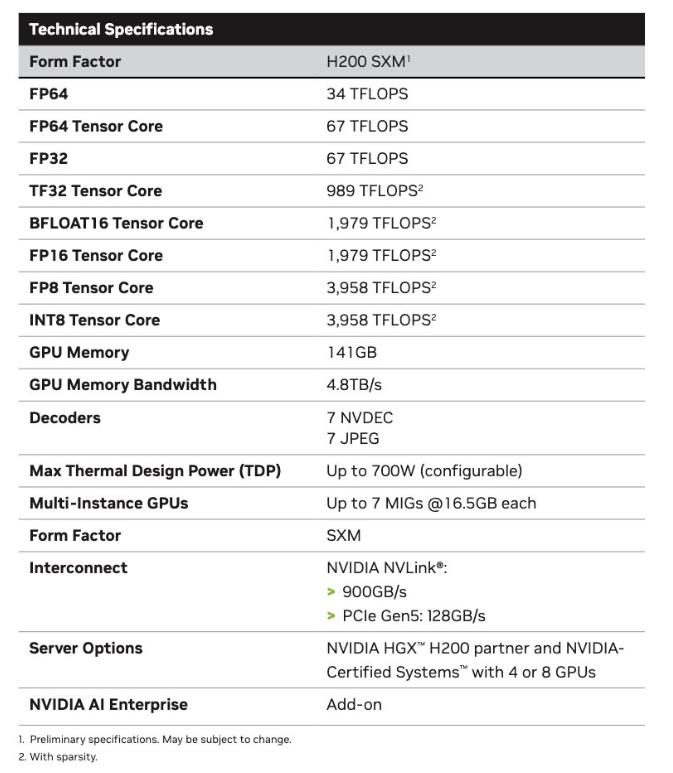
NVIDIA H200 Tensor Core GPUs pack HBM3e memory to run growing generative AI models.
Share
NVIDIA today unveiled at SC23 the next wave of technologies that will lift scientific and industrial research centers worldwide to new levels of performance and energy efficiency.
“NVIDIA hardware and software innovations are creating a new class of AI supercomputers,” said Ian Buck, vice president of the company’s high performance computing and hyperscale data center business, in a special address at the conference.
Some of the systems will pack memory-enhanced NVIDIA Hopper accelerators, others a new NVIDIA Grace Hopper systems architecture. All will use the expanded parallelism to run a full stack of accelerated software for generative AI, HPC and hybrid quantum computing.
Buck described the new NVIDIA HGX H200 as “the world’s leading AI computing platform.”
Image of H200 GPU system
NVIDIA H200 Tensor Core GPUs pack HBM3e memory to run growing generative AI models.
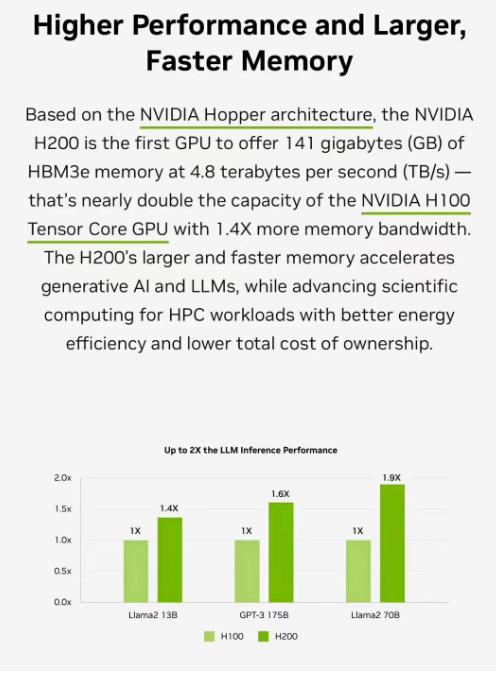
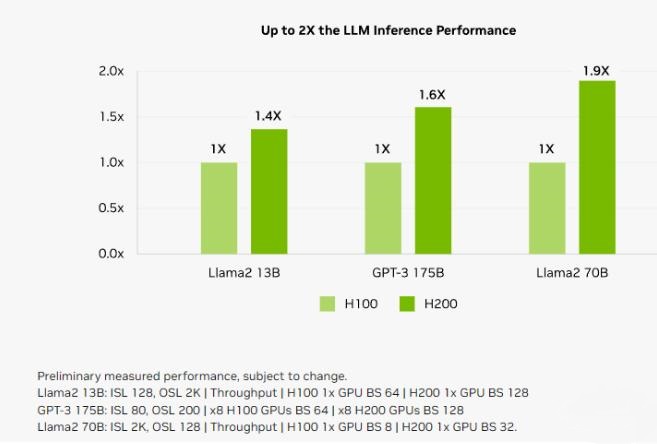
It packs up to 141GB of HBM3e, the first AI accelerator to use the ultrafast technology. Running models like GPT-3, NVIDIA H200 Tensor Core GPUs provide an 18x performance increase over prior-generation accelerators.
Among other generative AI benchmarks, they zip through 12,000 tokens per second on a Llama2-13B large language model (LLM).
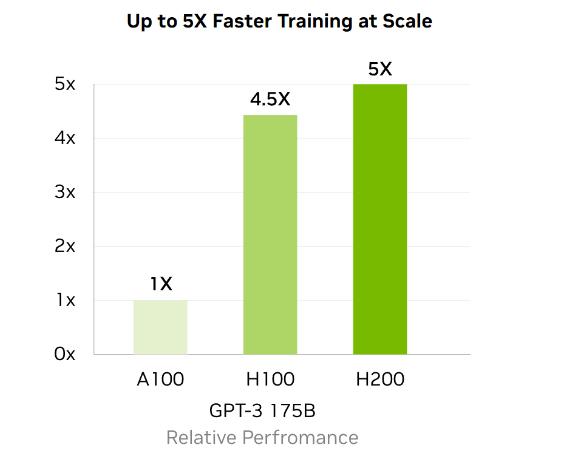
Buck also revealed a server platform that links four NVIDIA GH200 Grace Hopper Superchips on an NVIDIA NVLink interconnect. The quad configuration puts in a single compute node a whopping 288 Arm Neoverse cores and 16 petaflops of AI performance with up to 2.3 terabytes of high-speed memory.

Server nodes based on the four GH200 Superchips will deliver 16 petaflops of AI performance.
Share
NVIDIA today unveiled at SC23 the next wave of technologies that will lift scientific and industrial research centers worldwide to new levels of performance and energy efficiency.
“NVIDIA hardware and software innovations are creating a new class of AI supercomputers,” said Ian Buck, vice president of the company’s high performance computing and hyperscale data center business, in a special address at the conference.
Some of the systems will pack memory-enhanced NVIDIA Hopper accelerators, others a new NVIDIA Grace Hopper systems architecture. All will use the expanded parallelism to run a full stack of accelerated software for generative AI, HPC and hybrid quantum computing.
Buck described the new NVIDIA HGX H200 as “the world’s leading AI computing platform.”
Image of H200 GPU system
NVIDIA H200 Tensor Core GPUs pack HBM3e memory to run growing generative AI models.
It packs up to 141GB of HBM3e, the first AI accelerator to use the ultrafast technology. Running models like GPT-3, NVIDIA H200 Tensor Core GPUs provide an 18x performance increase over prior-generation accelerators.
Among other generative AI benchmarks, they zip through 12,000 tokens per second on a Llama2-13B large language model (LLM).
Buck also revealed a server platform that links four NVIDIA GH200 Grace Hopper Superchips on an NVIDIA NVLink interconnect. The quad configuration puts in a single compute node a whopping 288 Arm Neoverse cores and 16 petaflops of AI performance with up to 2.3 terabytes of high-speed memory.
Image of quad GH200 server node
Server nodes based on the four GH200 Superchips will deliver 16 petaflops of AI performance.
Demonstrating its efficiency, one GH200 Superchip using the NVIDIA TensorRT-LLM open-source library is 100x faster than a dual-socket x86 CPU system and nearly 2x more energy efficient than an X86 + H100 GPU server.
“Accelerated computing is sustainable computing,” Buck said. “By harnessing the power of accelerated computing and generative AI, together we can drive innovation across industries while reducing our impact on the environment.”
NVIDIA Powers 38 of 49 New TOP500 Systems
The latest TOP500 list of the world’s fastest supercomputers reflects the shift toward accelerated, energy-efficient supercomputing.
Thanks to new systems powered by NVIDIA H100 Tensor Core GPUs, NVIDIA now delivers more than 2.5 exaflops of HPC performance across these world-leading systems, up from 1.6 exaflops in the May rankings. NVIDIA’s contribution on the top 10 alone reaches nearly an exaflop of HPC and 72 exaflops of AI performance.
The new list contains the highest number of systems ever using NVIDIA technologies, 379 vs. 372 in May, including 38 of 49 new supercomputers on the list.
Microsoft Azure leads the newcomers with its Eagle system using H100 GPUs in NDv5 instances to hit No. 3 with 561 petaflops. Mare Nostrum5 in Barcelona ranked No. 8, and NVIDIA Eos — which recently set new AI training records on the MLPerf benchmarks — came in at No. 9.
Showing their energy efficiency, NVIDIA GPUs power 23 of the top 30 systems on the Green500. And they retained the No. 1 spot with the H100 GPU-based Henri system, which delivers 65.09 gigaflops per watt for the Flatiron Institute in New York.
Gen AI Explores COVID
Share
NVIDIA today unveiled at SC23 the next wave of technologies that will lift scientific and industrial research centers worldwide to new levels of performance and energy efficiency.
“NVIDIA hardware and software innovations are creating a new class of AI supercomputers,” said Ian Buck, vice president of the company’s high performance computing and hyperscale data center business, in a special address at the conference.
Some of the systems will pack memory-enhanced NVIDIA Hopper accelerators, others a new NVIDIA Grace Hopper systems architecture. All will use the expanded parallelism to run a full stack of accelerated software for generative AI, HPC and hybrid quantum computing.
Buck described the new NVIDIA HGX H200 as “the world’s leading AI computing platform.”
Image of H200 GPU system
NVIDIA H200 Tensor Core GPUs pack HBM3e memory to run growing generative AI models.
It packs up to 141GB of HBM3e, the first AI accelerator to use the ultrafast technology. Running models like GPT-3, NVIDIA H200 Tensor Core GPUs provide an 18x performance increase over prior-generation accelerators.
Among other generative AI benchmarks, they zip through 12,000 tokens per second on a Llama2-13B large language model (LLM).
Buck also revealed a server platform that links four NVIDIA GH200 Grace Hopper Superchips on an NVIDIA NVLink interconnect. The quad configuration puts in a single compute node a whopping 288 Arm Neoverse cores and 16 petaflops of AI performance with up to 2.3 terabytes of high-speed memory.
Image of quad GH200 server node
Server nodes based on the four GH200 Superchips will deliver 16 petaflops of AI performance.
Demonstrating its efficiency, one GH200 Superchip using the NVIDIA TensorRT-LLM open-source library is 100x faster than a dual-socket x86 CPU system and nearly 2x more energy efficient than an X86 + H100 GPU server.
“Accelerated computing is sustainable computing,” Buck said. “By harnessing the power of accelerated computing and generative AI, together we can drive innovation across industries while reducing our impact on the environment.”
NVIDIA Powers 38 of 49 New TOP500 Systems
The latest TOP500 list of the world’s fastest supercomputers reflects the shift toward accelerated, energy-efficient supercomputing.
Thanks to new systems powered by NVIDIA H100 Tensor Core GPUs, NVIDIA now delivers more than 2.5 exaflops of HPC performance across these world-leading systems, up from 1.6 exaflops in the May rankings. NVIDIA’s contribution on the top 10 alone reaches nearly an exaflop of HPC and 72 exaflops of AI performance.
The new list contains the highest number of systems ever using NVIDIA technologies, 379 vs. 372 in May, including 38 of 49 new supercomputers on the list.
Microsoft Azure leads the newcomers with its Eagle system using H100 GPUs in NDv5 instances to hit No. 3 with 561 petaflops. Mare Nostrum5 in Barcelona ranked No. 8, and NVIDIA Eos — which recently set new AI training records on the MLPerf benchmarks — came in at No. 9.
Showing their energy efficiency, NVIDIA GPUs power 23 of the top 30 systems on the Green500. And they retained the No. 1 spot with the H100 GPU-based Henri system, which delivers 65.09 gigaflops per watt for the Flatiron Institute in New York.
Gen AI Explores COVID
Showing what’s possible, the Argonne National Laboratory used NVIDIA BioNeMo, a generative AI platform for biomolecular LLMs, to develop GenSLMs, a model that can generate gene sequences that closely resemble real-world variants of the coronavirus. Using NVIDIA GPUs and data from 1.5 million COVID genome sequences, it can also rapidly identify new virus variants.
The work won the Gordon Bell special prize last year and was trained on supercomputers, including Argonne’s Polaris system, the U.S. Department of Energy’s Perlmutter and NVIDIA’s Selene.
It’s “just the tip of the iceberg — the future is brimming with possibilities, as generative AI continues to redefine the landscape of scientific exploration,” said Kimberly Powell, vice president of healthcare at NVIDIA, in the special address.
Saving Time, Money and Energy
Using the latest technologies, accelerated workloads can see an order-of-magnitude reduction in system cost and energy used, Buck said.
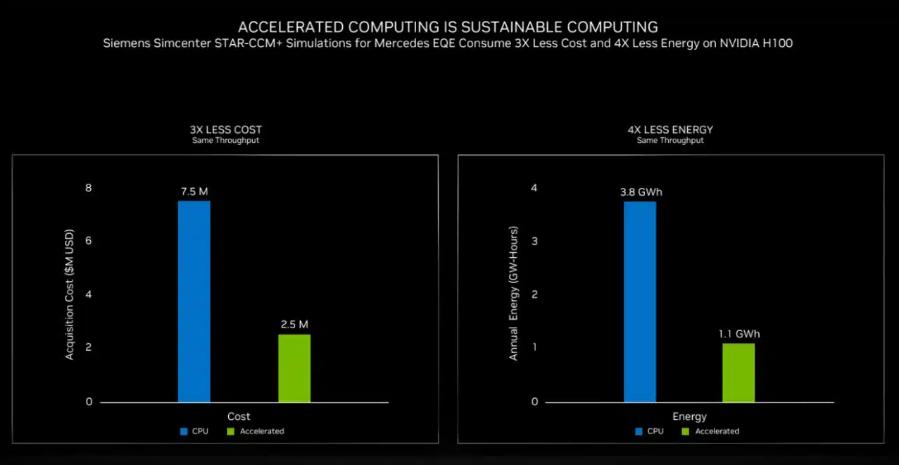
For example, Siemens teamed with Mercedes to analyze aerodynamics and related acoustics for its new electric EQE vehicles. The simulations that took weeks on CPU clusters ran significantly faster using the latest NVIDIA H100 GPUs. In addition, Hopper GPUs let them reduce costs by 3x and reduce energy consumption by 4x (below).
Switching on 200 Exaflops Beginning Next Year
Scientific and industrial advances will come from every corner of the globe where the latest systems are being deployed.
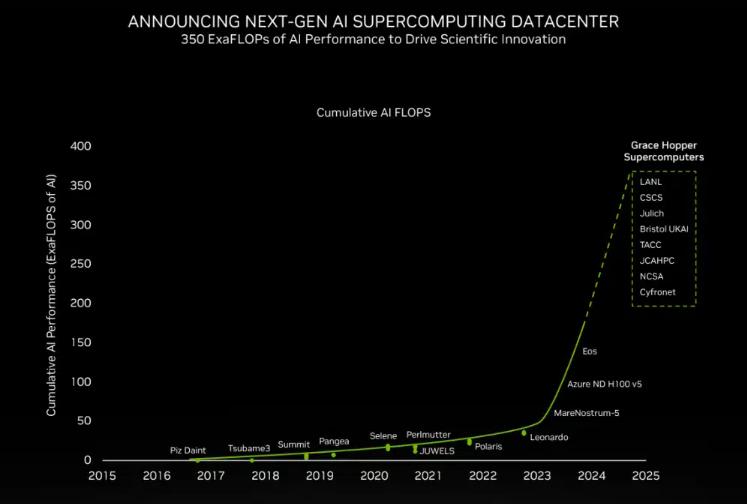
“We already see a combined 200 exaflops of AI on Grace Hopper supercomputers going to production 2024,” Buck said.
They include the massive JUPITER supercomputer at Germany’s Jülich center. It can deliver 93 exaflops of performance for AI training and 1 exaflop for HPC applications, while consuming only 18.2 megawatts of power.
Research centers are poised to switch on a tsunami of GH200 performance.
Based on Eviden’s BullSequana XH3000 liquid-cooled system, JUPITER will use the NVIDIA quad GH200 system architecture and NVIDIA Quantum-2 InfiniBand networking for climate and weather predictions, drug discovery, hybrid quantum computing and digital twins. JUPITER quad GH200 nodes will be configured with 864GB of high-speed memory.
It’s one of several new supercomputers using Grace Hopper that NVIDIA announced at SC23.
The HPE Cray EX2500 system from Hewlett Packard Enterprise will use the quad GH200 to power many AI supercomputers coming online next year.
For example, HPE uses the quad GH200 to power OFP-II, an advanced HPC system in Japan shared by the University of Tsukuba and the University of Tokyo, as well as the DeltaAI system, which will triple computing capacity for the U.S. National Center for Supercomputing Applications.
HPE is also building the Venado system for the Los Alamos National Laboratory, the first GH200 to be deployed in the U.S. In addition, HPE is building GH200 supercomputers in the Middle East, Switzerland and the U.K.
Grace Hopper in Texas and Beyond
Share
NVIDIA today unveiled at SC23 the next wave of technologies that will lift scientific and industrial research centers worldwide to new levels of performance and energy efficiency.
“NVIDIA hardware and software innovations are creating a new class of AI supercomputers,” said Ian Buck, vice president of the company’s high performance computing and hyperscale data center business, in a special address at the conference.
Some of the systems will pack memory-enhanced NVIDIA Hopper accelerators, others a new NVIDIA Grace Hopper systems architecture. All will use the expanded parallelism to run a full stack of accelerated software for generative AI, HPC and hybrid quantum computing.
Buck described the new NVIDIA HGX H200 as “the world’s leading AI computing platform.”
Image of H200 GPU system
NVIDIA H200 Tensor Core GPUs pack HBM3e memory to run growing generative AI models.
It packs up to 141GB of HBM3e, the first AI accelerator to use the ultrafast technology. Running models like GPT-3, NVIDIA H200 Tensor Core GPUs provide an 18x performance increase over prior-generation accelerators.
Among other generative AI benchmarks, they zip through 12,000 tokens per second on a Llama2-13B large language model (LLM).
Buck also revealed a server platform that links four NVIDIA GH200 Grace Hopper Superchips on an NVIDIA NVLink interconnect. The quad configuration puts in a single compute node a whopping 288 Arm Neoverse cores and 16 petaflops of AI performance with up to 2.3 terabytes of high-speed memory.
Image of quad GH200 server node
Server nodes based on the four GH200 Superchips will deliver 16 petaflops of AI performance.
Demonstrating its efficiency, one GH200 Superchip using the NVIDIA TensorRT-LLM open-source library is 100x faster than a dual-socket x86 CPU system and nearly 2x more energy efficient than an X86 + H100 GPU server.
“Accelerated computing is sustainable computing,” Buck said. “By harnessing the power of accelerated computing and generative AI, together we can drive innovation across industries while reducing our impact on the environment.”
NVIDIA Powers 38 of 49 New TOP500 Systems
The latest TOP500 list of the world’s fastest supercomputers reflects the shift toward accelerated, energy-efficient supercomputing.
Thanks to new systems powered by NVIDIA H100 Tensor Core GPUs, NVIDIA now delivers more than 2.5 exaflops of HPC performance across these world-leading systems, up from 1.6 exaflops in the May rankings. NVIDIA’s contribution on the top 10 alone reaches nearly an exaflop of HPC and 72 exaflops of AI performance.
The new list contains the highest number of systems ever using NVIDIA technologies, 379 vs. 372 in May, including 38 of 49 new supercomputers on the list.
Microsoft Azure leads the newcomers with its Eagle system using H100 GPUs in NDv5 instances to hit No. 3 with 561 petaflops. Mare Nostrum5 in Barcelona ranked No. 8, and NVIDIA Eos — which recently set new AI training records on the MLPerf benchmarks — came in at No. 9.
Showing their energy efficiency, NVIDIA GPUs power 23 of the top 30 systems on the Green500. And they retained the No. 1 spot with the H100 GPU-based Henri system, which delivers 65.09 gigaflops per watt for the Flatiron Institute in New York.
Gen AI Explores COVID
Showing what’s possible, the Argonne National Laboratory used NVIDIA BioNeMo, a generative AI platform for biomolecular LLMs, to develop GenSLMs, a model that can generate gene sequences that closely resemble real-world variants of the coronavirus. Using NVIDIA GPUs and data from 1.5 million COVID genome sequences, it can also rapidly identify new virus variants.
The work won the Gordon Bell special prize last year and was trained on supercomputers, including Argonne’s Polaris system, the U.S. Department of Energy’s Perlmutter and NVIDIA’s Selene.
It’s “just the tip of the iceberg — the future is brimming with possibilities, as generative AI continues to redefine the landscape of scientific exploration,” said Kimberly Powell, vice president of healthcare at NVIDIA, in the special address.
Saving Time, Money and Energy
Using the latest technologies, accelerated workloads can see an order-of-magnitude reduction in system cost and energy used, Buck said.
For example, Siemens teamed with Mercedes to analyze aerodynamics and related acoustics for its new electric EQE vehicles. The simulations that took weeks on CPU clusters ran significantly faster using the latest NVIDIA H100 GPUs. In addition, Hopper GPUs let them reduce costs by 3x and reduce energy consumption by 4x (below).
Chart showing the performance and energy efficiency of H100 GPUs
Switching on 200 Exaflops Beginning Next Year
Scientific and industrial advances will come from every corner of the globe where the latest systems are being deployed.
“We already see a combined 200 exaflops of AI on Grace Hopper supercomputers going to production 2024,” Buck said.
They include the massive JUPITER supercomputer at Germany’s Jülich center. It can deliver 93 exaflops of performance for AI training and 1 exaflop for HPC applications, while consuming only 18.2 megawatts of power.
Chart of deployed performance of supercomputers using NVIDIA GPUs through 2024
Research centers are poised to switch on a tsunami of GH200 performance.
Based on Eviden’s BullSequana XH3000 liquid-cooled system, JUPITER will use the NVIDIA quad GH200 system architecture and NVIDIA Quantum-2 InfiniBand networking for climate and weather predictions, drug discovery, hybrid quantum computing and digital twins. JUPITER quad GH200 nodes will be configured with 864GB of high-speed memory.
It’s one of several new supercomputers using Grace Hopper that NVIDIA announced at SC23.
The HPE Cray EX2500 system from Hewlett Packard Enterprise will use the quad GH200 to power many AI supercomputers coming online next year.
For example, HPE uses the quad GH200 to power OFP-II, an advanced HPC system in Japan shared by the University of Tsukuba and the University of Tokyo, as well as the DeltaAI system, which will triple computing capacity for the U.S. National Center for Supercomputing Applications.
HPE is also building the Venado system for the Los Alamos National Laboratory, the first GH200 to be deployed in the U.S. In addition, HPE is building GH200 supercomputers in the Middle East, Switzerland and the U.K.
Grace Hopper in Texas and Beyond
At the Texas Advanced Computing Center (TACC), Dell Technologies is building the Vista supercomputer with NVIDIA Grace Hopper and Grace CPU Superchips.
More than 100 global enterprises and organizations, including NASA Ames Research Center and Total Energies, have already purchased Grace Hopper early-access systems, Buck said.
They join previously announced GH200 users such as SoftBank and the University of Bristol, as well as the massive Leonardo system with 14,000 NVIDIA A100 GPUs that delivers 10 exaflops of AI performance for Italy’s Cineca consortium.
The View From Supercomputing Centers
Leaders from supercomputing centers around the world shared their plans and work in progress with the latest systems.
“We’ve been collaborating with MeteoSwiss ECMWP as well as scientists from ETH EXCLAIM and NVIDIA’s Earth-2 project to create an infrastructure that will push the envelope in all dimensions of big data analytics and extreme scale computing,” said Thomas Schultess, director of the Swiss National Supercomputing Centre of work on the Alps supercomputer.
“There’s really impressive energy-efficiency gains across our stacks,” Dan Stanzione, executive director of TACC, said of Vista.
It’s “really the stepping stone to move users from the kinds of systems we’ve done in the past to looking at this new Grace Arm CPU and Hopper GPU tightly coupled combination and … we’re looking to scale out by probably a factor of 10 or 15 from what we are deploying with Vista when we deploy Horizon in a couple years,” he said.
Accelerating the Quantum Journey
Researchers are also using today’s accelerated systems to pioneer a path to tomorrow’s supercomputers.
In Germany, JUPITER “will revolutionize scientific research across climate, materials, drug discovery and quantum computing,” said Kristel Michelson, who leads Julich’s research group on quantum information processing.
Share
NVIDIA today unveiled at SC23 the next wave of technologies that will lift scientific and industrial research centers worldwide to new levels of performance and energy efficiency.
“NVIDIA hardware and software innovations are creating a new class of AI supercomputers,” said Ian Buck, vice president of the company’s high performance computing and hyperscale data center business, in a special address at the conference.
Some of the systems will pack memory-enhanced NVIDIA Hopper accelerators, others a new NVIDIA Grace Hopper systems architecture. All will use the expanded parallelism to run a full stack of accelerated software for generative AI, HPC and hybrid quantum computing.
Buck described the new NVIDIA HGX H200 as “the world’s leading AI computing platform.”
Image of H200 GPU system
NVIDIA H200 Tensor Core GPUs pack HBM3e memory to run growing generative AI models.
It packs up to 141GB of HBM3e, the first AI accelerator to use the ultrafast technology. Running models like GPT-3, NVIDIA H200 Tensor Core GPUs provide an 18x performance increase over prior-generation accelerators.
Among other generative AI benchmarks, they zip through 12,000 tokens per second on a Llama2-13B large language model (LLM).
Buck also revealed a server platform that links four NVIDIA GH200 Grace Hopper Superchips on an NVIDIA NVLink interconnect. The quad configuration puts in a single compute node a whopping 288 Arm Neoverse cores and 16 petaflops of AI performance with up to 2.3 terabytes of high-speed memory.
Image of quad GH200 server node
Server nodes based on the four GH200 Superchips will deliver 16 petaflops of AI performance.
Demonstrating its efficiency, one GH200 Superchip using the NVIDIA TensorRT-LLM open-source library is 100x faster than a dual-socket x86 CPU system and nearly 2x more energy efficient than an X86 + H100 GPU server.
“Accelerated computing is sustainable computing,” Buck said. “By harnessing the power of accelerated computing and generative AI, together we can drive innovation across industries while reducing our impact on the environment.”
NVIDIA Powers 38 of 49 New TOP500 Systems
The latest TOP500 list of the world’s fastest supercomputers reflects the shift toward accelerated, energy-efficient supercomputing.
Thanks to new systems powered by NVIDIA H100 Tensor Core GPUs, NVIDIA now delivers more than 2.5 exaflops of HPC performance across these world-leading systems, up from 1.6 exaflops in the May rankings. NVIDIA’s contribution on the top 10 alone reaches nearly an exaflop of HPC and 72 exaflops of AI performance.
The new list contains the highest number of systems ever using NVIDIA technologies, 379 vs. 372 in May, including 38 of 49 new supercomputers on the list.
Microsoft Azure leads the newcomers with its Eagle system using H100 GPUs in NDv5 instances to hit No. 3 with 561 petaflops. Mare Nostrum5 in Barcelona ranked No. 8, and NVIDIA Eos — which recently set new AI training records on the MLPerf benchmarks — came in at No. 9.
Showing their energy efficiency, NVIDIA GPUs power 23 of the top 30 systems on the Green500. And they retained the No. 1 spot with the H100 GPU-based Henri system, which delivers 65.09 gigaflops per watt for the Flatiron Institute in New York.
Gen AI Explores COVID
Showing what’s possible, the Argonne National Laboratory used NVIDIA BioNeMo, a generative AI platform for biomolecular LLMs, to develop GenSLMs, a model that can generate gene sequences that closely resemble real-world variants of the coronavirus. Using NVIDIA GPUs and data from 1.5 million COVID genome sequences, it can also rapidly identify new virus variants.
The work won the Gordon Bell special prize last year and was trained on supercomputers, including Argonne’s Polaris system, the U.S. Department of Energy’s Perlmutter and NVIDIA’s Selene.
It’s “just the tip of the iceberg — the future is brimming with possibilities, as generative AI continues to redefine the landscape of scientific exploration,” said Kimberly Powell, vice president of healthcare at NVIDIA, in the special address.
Saving Time, Money and Energy
Using the latest technologies, accelerated workloads can see an order-of-magnitude reduction in system cost and energy used, Buck said.
For example, Siemens teamed with Mercedes to analyze aerodynamics and related acoustics for its new electric EQE vehicles. The simulations that took weeks on CPU clusters ran significantly faster using the latest NVIDIA H100 GPUs. In addition, Hopper GPUs let them reduce costs by 3x and reduce energy consumption by 4x (below).
Chart showing the performance and energy efficiency of H100 GPUs
Switching on 200 Exaflops Beginning Next Year
Scientific and industrial advances will come from every corner of the globe where the latest systems are being deployed.
“We already see a combined 200 exaflops of AI on Grace Hopper supercomputers going to production 2024,” Buck said.
They include the massive JUPITER supercomputer at Germany’s Jülich center. It can deliver 93 exaflops of performance for AI training and 1 exaflop for HPC applications, while consuming only 18.2 megawatts of power.
Chart of deployed performance of supercomputers using NVIDIA GPUs through 2024
Research centers are poised to switch on a tsunami of GH200 performance.
Based on Eviden’s BullSequana XH3000 liquid-cooled system, JUPITER will use the NVIDIA quad GH200 system architecture and NVIDIA Quantum-2 InfiniBand networking for climate and weather predictions, drug discovery, hybrid quantum computing and digital twins. JUPITER quad GH200 nodes will be configured with 864GB of high-speed memory.
It’s one of several new supercomputers using Grace Hopper that NVIDIA announced at SC23.
The HPE Cray EX2500 system from Hewlett Packard Enterprise will use the quad GH200 to power many AI supercomputers coming online next year.
For example, HPE uses the quad GH200 to power OFP-II, an advanced HPC system in Japan shared by the University of Tsukuba and the University of Tokyo, as well as the DeltaAI system, which will triple computing capacity for the U.S. National Center for Supercomputing Applications.
HPE is also building the Venado system for the Los Alamos National Laboratory, the first GH200 to be deployed in the U.S. In addition, HPE is building GH200 supercomputers in the Middle East, Switzerland and the U.K.
Grace Hopper in Texas and Beyond
At the Texas Advanced Computing Center (TACC), Dell Technologies is building the Vista supercomputer with NVIDIA Grace Hopper and Grace CPU Superchips.
More than 100 global enterprises and organizations, including NASA Ames Research Center and Total Energies, have already purchased Grace Hopper early-access systems, Buck said.
They join previously announced GH200 users such as SoftBank and the University of Bristol, as well as the massive Leonardo system with 14,000 NVIDIA A100 GPUs that delivers 10 exaflops of AI performance for Italy’s Cineca consortium.
The View From Supercomputing Centers
Leaders from supercomputing centers around the world shared their plans and work in progress with the latest systems.
“We’ve been collaborating with MeteoSwiss ECMWP as well as scientists from ETH EXCLAIM and NVIDIA’s Earth-2 project to create an infrastructure that will push the envelope in all dimensions of big data analytics and extreme scale computing,” said Thomas Schultess, director of the Swiss National Supercomputing Centre of work on the Alps supercomputer.
“There’s really impressive energy-efficiency gains across our stacks,” Dan Stanzione, executive director of TACC, said of Vista.
It’s “really the stepping stone to move users from the kinds of systems we’ve done in the past to looking at this new Grace Arm CPU and Hopper GPU tightly coupled combination and … we’re looking to scale out by probably a factor of 10 or 15 from what we are deploying with Vista when we deploy Horizon in a couple years,” he said.
Accelerating the Quantum Journey
Researchers are also using today’s accelerated systems to pioneer a path to tomorrow’s supercomputers.
In Germany, JUPITER “will revolutionize scientific research across climate, materials, drug discovery and quantum computing,” said Kristel Michelson, who leads Julich’s research group on quantum information processing.
“JUPITER’s architecture also allows for the seamless integration of quantum algorithms with parallel HPC algorithms, and this is mandatory for effective quantum HPC hybrid simulations,” she said.
CUDA Quantum Drives Progress
The special address also showed how NVIDIA CUDA Quantum — a platform for programming CPUs, GPUs and quantum computers also known as QPUs — is advancing research in quantum computing.
For example, researchers at BASF, the world’s largest chemical company, pioneered a new hybrid quantum-classical method for simulating chemicals that can shield humans against harmful metals. They join researchers at Brookhaven National Laboratory and HPE who are separately pushing the frontiers of science with CUDA Quantum.
NVIDIA also announced a collaboration with Classiq, a developer of quantum programming tools, to create a life sciences research center at the Tel Aviv Sourasky Medical Center, Israel’s largest teaching hospital. The center will use Classiq’s software and CUDA Quantum running on an NVIDIA DGX H100 system.
Separately, Quantum Machines will deploy the first NVIDIA DGX Quantum, a system using Grace Hopper Superchips, at the Israel National Quantum Center that aims to drive advances across scientific fields. The DGX system will be connected to a superconducting QPU by Quantware and a photonic QPU from ORCA Computing, both powered
Research centers are poised to switch on a tsunami of GH200 performance.
Based on Eviden’s BullSequana XH3000 liquid-cooled system, JUPITER will use the NVIDIA quad GH200 system architecture and NVIDIA Quantum-2 InfiniBand networking for climate and weather predictions, drug discovery, hybrid quantum computing and digital twins. JUPITER quad GH200 nodes will be configured with 864GB of high-speed memory.
It’s one of several new supercomputers using Grace Hopper that NVIDIA announced at SC23.
The HPE Cray EX2500 system from Hewlett Packard Enterprise will use the quad GH200 to power many AI supercomputers coming online next year.
For example, HPE uses the quad GH200 to power OFP-II, an advanced HPC system in Japan shared by the University of Tsukuba and the University of Tokyo, as well as the DeltaAI system, which will triple computing capacity for the U.S. National Center for Supercomputing Applications.
HPE is also building the Venado system for the Los Alamos National Laboratory, the first GH200 to be deployed in the U.S. In addition, HPE is building GH200 supercomputers in the Middle East, Switzerland and the U.K.
Grace Hopper in Texas and Beyond
Share
NVIDIA today unveiled at SC23 the next wave of technologies that will lift scientific and industrial research centers worldwide to new levels of performance and energy efficiency.
“NVIDIA hardware and software innovations are creating a new class of AI supercomputers,” said Ian Buck, vice president of the company’s high performance computing and hyperscale data center business, in a special address at the conference.
Some of the systems will pack memory-enhanced NVIDIA Hopper accelerators, others a new NVIDIA Grace Hopper systems architecture. All will use the expanded parallelism to run a full stack of accelerated software for generative AI, HPC and hybrid quantum computing.
Buck described the new NVIDIA HGX H200 as “the world’s leading AI computing platform.”
Image of H200 GPU system
NVIDIA H200 Tensor Core GPUs pack HBM3e memory to run growing generative AI models.
It packs up to 141GB of HBM3e, the first AI accelerator to use the ultrafast technology. Running models like GPT-3, NVIDIA H200 Tensor Core GPUs provide an 18x performance increase over prior-generation accelerators.
Among other generative AI benchmarks, they zip through 12,000 tokens per second on a Llama2-13B large language model (LLM).
Buck also revealed a server platform that links four NVIDIA GH200 Grace Hopper Superchips on an NVIDIA NVLink interconnect. The quad configuration puts in a single compute node a whopping 288 Arm Neoverse cores and 16 petaflops of AI performance with up to 2.3 terabytes of high-speed memory.
Image of quad GH200 server node
Server nodes based on the four GH200 Superchips will deliver 16 petaflops of AI performance.
Demonstrating its efficiency, one GH200 Superchip using the NVIDIA TensorRT-LLM open-source library is 100x faster than a dual-socket x86 CPU system and nearly 2x more energy efficient than an X86 + H100 GPU server.
“Accelerated computing is sustainable computing,” Buck said. “By harnessing the power of accelerated computing and generative AI, together we can drive innovation across industries while reducing our impact on the environment.”
NVIDIA Powers 38 of 49 New TOP500 Systems
The latest TOP500 list of the world’s fastest supercomputers reflects the shift toward accelerated, energy-efficient supercomputing.
Thanks to new systems powered by NVIDIA H100 Tensor Core GPUs, NVIDIA now delivers more than 2.5 exaflops of HPC performance across these world-leading systems, up from 1.6 exaflops in the May rankings. NVIDIA’s contribution on the top 10 alone reaches nearly an exaflop of HPC and 72 exaflops of AI performance.
The new list contains the highest number of systems ever using NVIDIA technologies, 379 vs. 372 in May, including 38 of 49 new supercomputers on the list.
Microsoft Azure leads the newcomers with its Eagle system using H100 GPUs in NDv5 instances to hit No. 3 with 561 petaflops. Mare Nostrum5 in Barcelona ranked No. 8, and NVIDIA Eos — which recently set new AI training records on the MLPerf benchmarks — came in at No. 9.
Showing their energy efficiency, NVIDIA GPUs power 23 of the top 30 systems on the Green500. And they retained the No. 1 spot with the H100 GPU-based Henri system, which delivers 65.09 gigaflops per watt for the Flatiron Institute in New York.
Gen AI Explores COVID
Showing what’s possible, the Argonne National Laboratory used NVIDIA BioNeMo, a generative AI platform for biomolecular LLMs, to develop GenSLMs, a model that can generate gene sequences that closely resemble real-world variants of the coronavirus. Using NVIDIA GPUs and data from 1.5 million COVID genome sequences, it can also rapidly identify new virus variants.
The work won the Gordon Bell special prize last year and was trained on supercomputers, including Argonne’s Polaris system, the U.S. Department of Energy’s Perlmutter and NVIDIA’s Selene.
It’s “just the tip of the iceberg — the future is brimming with possibilities, as generative AI continues to redefine the landscape of scientific exploration,” said Kimberly Powell, vice president of healthcare at NVIDIA, in the special address.
Saving Time, Money and Energy
Using the latest technologies, accelerated workloads can see an order-of-magnitude reduction in system cost and energy used, Buck said.
For example, Siemens teamed with Mercedes to analyze aerodynamics and related acoustics for its new electric EQE vehicles. The simulations that took weeks on CPU clusters ran significantly faster using the latest NVIDIA H100 GPUs. In addition, Hopper GPUs let them reduce costs by 3x and reduce energy consumption by 4x (below).
Chart showing the performance and energy efficiency of H100 GPUs
Switching on 200 Exaflops Beginning Next Year
Scientific and industrial advances will come from every corner of the globe where the latest systems are being deployed.
“We already see a combined 200 exaflops of AI on Grace Hopper supercomputers going to production 2024,” Buck said.
They include the massive JUPITER supercomputer at Germany’s Jülich center. It can deliver 93 exaflops of performance for AI training and 1 exaflop for HPC applications, while consuming only 18.2 megawatts of power.
Chart of deployed performance of supercomputers using NVIDIA GPUs through 2024
Research centers are poised to switch on a tsunami of GH200 performance.
Based on Eviden’s BullSequana XH3000 liquid-cooled system, JUPITER will use the NVIDIA quad GH200 system architecture and NVIDIA Quantum-2 InfiniBand networking for climate and weather predictions, drug discovery, hybrid quantum computing and digital twins. JUPITER quad GH200 nodes will be configured with 864GB of high-speed memory.
It’s one of several new supercomputers using Grace Hopper that NVIDIA announced at SC23.
The HPE Cray EX2500 system from Hewlett Packard Enterprise will use the quad GH200 to power many AI supercomputers coming online next year.
For example, HPE uses the quad GH200 to power OFP-II, an advanced HPC system in Japan shared by the University of Tsukuba and the University of Tokyo, as well as the DeltaAI system, which will triple computing capacity for the U.S. National Center for Supercomputing Applications.
HPE is also building the Venado system for the Los Alamos National Laboratory, the first GH200 to be deployed in the U.S. In addition, HPE is building GH200 supercomputers in the Middle East, Switzerland and the U.K.
Grace Hopper in Texas and Beyond
At the Texas Advanced Computing Center (TACC), Dell Technologies is building the Vista supercomputer with NVIDIA Grace Hopper and Grace CPU Superchips.
More than 100 global enterprises and organizations, including NASA Ames Research Center and Total Energies, have already purchased Grace Hopper early-access systems, Buck said.
They join previously announced GH200 users such as SoftBank and the University of Bristol, as well as the massive Leonardo system with 14,000 NVIDIA A100 GPUs that delivers 10 exaflops of AI performance for Italy’s Cineca consortium.
The View From Supercomputing Centers
Leaders from supercomputing centers around the world shared their plans and work in progress with the latest systems.
“We’ve been collaborating with MeteoSwiss ECMWP as well as scientists from ETH EXCLAIM and NVIDIA’s Earth-2 project to create an infrastructure that will push the envelope in all dimensions of big data analytics and extreme scale computing,” said Thomas Schultess, director of the Swiss National Supercomputing Centre of work on the Alps supercomputer.
“There’s really impressive energy-efficiency gains across our stacks,” Dan Stanzione, executive director of TACC, said of Vista.
It’s “really the stepping stone to move users from the kinds of systems we’ve done in the past to looking at this new Grace Arm CPU and Hopper GPU tightly coupled combination and … we’re looking to scale out by probably a factor of 10 or 15 from what we are deploying with Vista when we deploy Horizon in a couple years,” he said.
Accelerating the Quantum Journey
Researchers are also using today’s accelerated systems to pioneer a path to tomorrow’s supercomputers.
In Germany, JUPITER “will revolutionize scientific research across climate, materials, drug discovery and quantum computing,” said Kristel Michelson, who leads Julich’s research group on quantum information processing.
Share
NVIDIA today unveiled at SC23 the next wave of technologies that will lift scientific and industrial research centers worldwide to new levels of performance and energy efficiency.
“NVIDIA hardware and software innovations are creating a new class of AI supercomputers,” said Ian Buck, vice president of the company’s high performance computing and hyperscale data center business, in a special address at the conference.
Some of the systems will pack memory-enhanced NVIDIA Hopper accelerators, others a new NVIDIA Grace Hopper systems architecture. All will use the expanded parallelism to run a full stack of accelerated software for generative AI, HPC and hybrid quantum computing.
Buck described the new NVIDIA HGX H200 as “the world’s leading AI computing platform.”
Image of H200 GPU system
NVIDIA H200 Tensor Core GPUs pack HBM3e memory to run growing generative AI models.
It packs up to 141GB of HBM3e, the first AI accelerator to use the ultrafast technology. Running models like GPT-3, NVIDIA H200 Tensor Core GPUs provide an 18x performance increase over prior-generation accelerators.
Among other generative AI benchmarks, they zip through 12,000 tokens per second on a Llama2-13B large language model (LLM).
Buck also revealed a server platform that links four NVIDIA GH200 Grace Hopper Superchips on an NVIDIA NVLink interconnect. The quad configuration puts in a single compute node a whopping 288 Arm Neoverse cores and 16 petaflops of AI performance with up to 2.3 terabytes of high-speed memory.
Image of quad GH200 server node
Server nodes based on the four GH200 Superchips will deliver 16 petaflops of AI performance.
Demonstrating its efficiency, one GH200 Superchip using the NVIDIA TensorRT-LLM open-source library is 100x faster than a dual-socket x86 CPU system and nearly 2x more energy efficient than an X86 + H100 GPU server.
“Accelerated computing is sustainable computing,” Buck said. “By harnessing the power of accelerated computing and generative AI, together we can drive innovation across industries while reducing our impact on the environment.”
NVIDIA Powers 38 of 49 New TOP500 Systems
The latest TOP500 list of the world’s fastest supercomputers reflects the shift toward accelerated, energy-efficient supercomputing.
Thanks to new systems powered by NVIDIA H100 Tensor Core GPUs, NVIDIA now delivers more than 2.5 exaflops of HPC performance across these world-leading systems, up from 1.6 exaflops in the May rankings. NVIDIA’s contribution on the top 10 alone reaches nearly an exaflop of HPC and 72 exaflops of AI performance.
The new list contains the highest number of systems ever using NVIDIA technologies, 379 vs. 372 in May, including 38 of 49 new supercomputers on the list.
Microsoft Azure leads the newcomers with its Eagle system using H100 GPUs in NDv5 instances to hit No. 3 with 561 petaflops. Mare Nostrum5 in Barcelona ranked No. 8, and NVIDIA Eos — which recently set new AI training records on the MLPerf benchmarks — came in at No. 9.
Showing their energy efficiency, NVIDIA GPUs power 23 of the top 30 systems on the Green500. And they retained the No. 1 spot with the H100 GPU-based Henri system, which delivers 65.09 gigaflops per watt for the Flatiron Institute in New York.
Gen AI Explores COVID
Showing what’s possible, the Argonne National Laboratory used NVIDIA BioNeMo, a generative AI platform for biomolecular LLMs, to develop GenSLMs, a model that can generate gene sequences that closely resemble real-world variants of the coronavirus. Using NVIDIA GPUs and data from 1.5 million COVID genome sequences, it can also rapidly identify new virus variants.
The work won the Gordon Bell special prize last year and was trained on supercomputers, including Argonne’s Polaris system, the U.S. Department of Energy’s Perlmutter and NVIDIA’s Selene.
It’s “just the tip of the iceberg — the future is brimming with possibilities, as generative AI continues to redefine the landscape of scientific exploration,” said Kimberly Powell, vice president of healthcare at NVIDIA, in the special address.
Saving Time, Money and Energy
Using the latest technologies, accelerated workloads can see an order-of-magnitude reduction in system cost and energy used, Buck said.
For example, Siemens teamed with Mercedes to analyze aerodynamics and related acoustics for its new electric EQE vehicles. The simulations that took weeks on CPU clusters ran significantly faster using the latest NVIDIA H100 GPUs. In addition, Hopper GPUs let them reduce costs by 3x and reduce energy consumption by 4x (below).
Chart showing the performance and energy efficiency of H100 GPUs
Switching on 200 Exaflops Beginning Next Year
Scientific and industrial advances will come from every corner of the globe where the latest systems are being deployed.
“We already see a combined 200 exaflops of AI on Grace Hopper supercomputers going to production 2024,” Buck said.
They include the massive JUPITER supercomputer at Germany’s Jülich center. It can deliver 93 exaflops of performance for AI training and 1 exaflop for HPC applications, while consuming only 18.2 megawatts of power.
Chart of deployed performance of supercomputers using NVIDIA GPUs through 2024
Research centers are poised to switch on a tsunami of GH200 performance.
Based on Eviden’s BullSequana XH3000 liquid-cooled system, JUPITER will use the NVIDIA quad GH200 system architecture and NVIDIA Quantum-2 InfiniBand networking for climate and weather predictions, drug discovery, hybrid quantum computing and digital twins. JUPITER quad GH200 nodes will be configured with 864GB of high-speed memory.
It’s one of several new supercomputers using Grace Hopper that NVIDIA announced at SC23.
The HPE Cray EX2500 system from Hewlett Packard Enterprise will use the quad GH200 to power many AI supercomputers coming online next year.
For example, HPE uses the quad GH200 to power OFP-II, an advanced HPC system in Japan shared by the University of Tsukuba and the University of Tokyo, as well as the DeltaAI system, which will triple computing capacity for the U.S. National Center for Supercomputing Applications.
HPE is also building the Venado system for the Los Alamos National Laboratory, the first GH200 to be deployed in the U.S. In addition, HPE is building GH200 supercomputers in the Middle East, Switzerland and the U.K.
Grace Hopper in Texas and Beyond
At the Texas Advanced Computing Center (TACC), Dell Technologies is building the Vista supercomputer with NVIDIA Grace Hopper and Grace CPU Superchips.
More than 100 global enterprises and organizations, including NASA Ames Research Center and Total Energies, have already purchased Grace Hopper early-access systems, Buck said.
They join previously announced GH200 users such as SoftBank and the University of Bristol, as well as the massive Leonardo system with 14,000 NVIDIA A100 GPUs that delivers 10 exaflops of AI performance for Italy’s Cineca consortium.
The View From Supercomputing Centers
Leaders from supercomputing centers around the world shared their plans and work in progress with the latest systems.
“We’ve been collaborating with MeteoSwiss ECMWP as well as scientists from ETH EXCLAIM and NVIDIA’s Earth-2 project to create an infrastructure that will push the envelope in all dimensions of big data analytics and extreme scale computing,” said Thomas Schultess, director of the Swiss National Supercomputing Centre of work on the Alps supercomputer.
“There’s really impressive energy-efficiency gains across our stacks,” Dan Stanzione, executive director of TACC, said of Vista.
It’s “really the stepping stone to move users from the kinds of systems we’ve done in the past to looking at this new Grace Arm CPU and Hopper GPU tightly coupled combination and … we’re looking to scale out by probably a factor of 10 or 15 from what we are deploying with Vista when we deploy Horizon in a couple years,” he said.
Accelerating the Quantum Journey
Researchers are also using today’s accelerated systems to pioneer a path to tomorrow’s supercomputers.
In Germany, JUPITER “will revolutionize scientific research across climate, materials, drug discovery and quantum computing,” said Kristel Michelson, who leads Julich’s research group on quantum information processing.
“JUPITER’s architecture also allows for the seamless integration of quantum algorithms with parallel HPC algorithms, and this is mandatory for effective quantum HPC hybrid simulations,” she said.
CUDA Quantum Drives Progress
The special address also showed how NVIDIA CUDA Quantum — a platform for programming CPUs, GPUs and quantum computers also known as QPUs — is advancing research in quantum computing.
For example, researchers at BASF, the world’s largest chemical company, pioneered a new hybrid quantum-classical method for simulating chemicals that can shield humans against harmful metals. They join researchers at Brookhaven National Laboratory and HPE who are separately pushing the frontiers of science with CUDA Quantum.
NVIDIA also announced a collaboration with Classiq, a developer of quantum programming tools, to create a life sciences research center at the Tel Aviv Sourasky Medical Center, Israel’s largest teaching hospital. The center will use Classiq’s software and CUDA Quantum running on an NVIDIA DGX H100 system.
Separately, Quantum Machines will deploy the first NVIDIA DGX Quantum, a system using Grace Hopper Superchips, at the Israel National Quantum Center that aims to drive advances across scientific fields. The DGX system will be connected to a superconducting QPU by Quantware and a photonic QPU from ORCA Computing, both powered
Research centers are poised to switch on a tsunami of GH200 performance.
Based on Eviden’s BullSequana XH3000 liquid-cooled system, JUPITER will use the NVIDIA quad GH200 system architecture and NVIDIA Quantum-2 InfiniBand networking for climate and weather predictions, drug discovery, hybrid quantum computing and digital twins. JUPITER quad GH200 nodes will be configured with 864GB of high-speed memory.
It’s one of several new supercomputers using Grace Hopper that NVIDIA announced at SC23.
The HPE Cray EX2500 system from Hewlett Packard Enterprise will use the quad GH200 to power many AI supercomputers coming online next year.
For example, HPE uses the quad GH200 to power OFP-II, an advanced HPC system in Japan shared by the University of Tsukuba and the University of Tokyo, as well as the DeltaAI system, which will triple computing capacity for the U.S. National Center for Supercomputing Applications.
HPE is also building the Venado system for the Los Alamos National Laboratory, the first GH200 to be deployed in the U.S. In addition, HPE is building GH200 supercomputers in the Middle East, Switzerland and the U.K.
Grace Hopper in Texas and Beyond
Share
NVIDIA today unveiled at SC23 the next wave of technologies that will lift scientific and industrial research centers worldwide to new levels of performance and energy efficiency.
“NVIDIA hardware and software innovations are creating a new class of AI supercomputers,” said Ian Buck, vice president of the company’s high performance computing and hyperscale data center business, in a special address at the conference.
Some of the systems will pack memory-enhanced NVIDIA Hopper accelerators, others a new NVIDIA Grace Hopper systems architecture. All will use the expanded parallelism to run a full stack of accelerated software for generative AI, HPC and hybrid quantum computing.
Buck described the new NVIDIA HGX H200 as “the world’s leading AI computing platform.”
Image of H200 GPU system
NVIDIA H200 Tensor Core GPUs pack HBM3e memory to run growing generative AI models.
It packs up to 141GB of HBM3e, the first AI accelerator to use the ultrafast technology. Running models like GPT-3, NVIDIA H200 Tensor Core GPUs provide an 18x performance increase over prior-generation accelerators.
Among other generative AI benchmarks, they zip through 12,000 tokens per second on a Llama2-13B large language model (LLM).
Buck also revealed a server platform that links four NVIDIA GH200 Grace Hopper Superchips on an NVIDIA NVLink interconnect. The quad configuration puts in a single compute node a whopping 288 Arm Neoverse cores and 16 petaflops of AI performance with up to 2.3 terabytes of high-speed memory.
Image of quad GH200 server node
Server nodes based on the four GH200 Superchips will deliver 16 petaflops of AI performance.
Demonstrating its efficiency, one GH200 Superchip using the NVIDIA TensorRT-LLM open-source library is 100x faster than a dual-socket x86 CPU system and nearly 2x more energy efficient than an X86 + H100 GPU server.
“Accelerated computing is sustainable computing,” Buck said. “By harnessing the power of accelerated computing and generative AI, together we can drive innovation across industries while reducing our impact on the environment.”
NVIDIA Powers 38 of 49 New TOP500 Systems
The latest TOP500 list of the world’s fastest supercomputers reflects the shift toward accelerated, energy-efficient supercomputing.
Thanks to new systems powered by NVIDIA H100 Tensor Core GPUs, NVIDIA now delivers more than 2.5 exaflops of HPC performance across these world-leading systems, up from 1.6 exaflops in the May rankings. NVIDIA’s contribution on the top 10 alone reaches nearly an exaflop of HPC and 72 exaflops of AI performance.
The new list contains the highest number of systems ever using NVIDIA technologies, 379 vs. 372 in May, including 38 of 49 new supercomputers on the list.
Microsoft Azure leads the newcomers with its Eagle system using H100 GPUs in NDv5 instances to hit No. 3 with 561 petaflops. Mare Nostrum5 in Barcelona ranked No. 8, and NVIDIA Eos — which recently set new AI training records on the MLPerf benchmarks — came in at No. 9.
Showing their energy efficiency, NVIDIA GPUs power 23 of the top 30 systems on the Green500. And they retained the No. 1 spot with the H100 GPU-based Henri system, which delivers 65.09 gigaflops per watt for the Flatiron Institute in New York.
Gen AI Explores COVID
Showing what’s possible, the Argonne National Laboratory used NVIDIA BioNeMo, a generative AI platform for biomolecular LLMs, to develop GenSLMs, a model that can generate gene sequences that closely resemble real-world variants of the coronavirus. Using NVIDIA GPUs and data from 1.5 million COVID genome sequences, it can also rapidly identify new virus variants.
The work won the Gordon Bell special prize last year and was trained on supercomputers, including Argonne’s Polaris system, the U.S. Department of Energy’s Perlmutter and NVIDIA’s Selene.
It’s “just the tip of the iceberg — the future is brimming with possibilities, as generative AI continues to redefine the landscape of scientific exploration,” said Kimberly Powell, vice president of healthcare at NVIDIA, in the special address.
Saving Time, Money and Energy
Using the latest technologies, accelerated workloads can see an order-of-magnitude reduction in system cost and energy used, Buck said.
For example, Siemens teamed with Mercedes to analyze aerodynamics and related acoustics for its new electric EQE vehicles. The simulations that took weeks on CPU clusters ran significantly faster using the latest NVIDIA H100 GPUs. In addition, Hopper GPUs let them reduce costs by 3x and reduce energy consumption by 4x (below).
Chart showing the performance and energy efficiency of H100 GPUs
Switching on 200 Exaflops Beginning Next Year
Scientific and industrial advances will come from every corner of the globe where the latest systems are being deployed.
“We already see a combined 200 exaflops of AI on Grace Hopper supercomputers going to production 2024,” Buck said.
They include the massive JUPITER supercomputer at Germany’s Jülich center. It can deliver 93 exaflops of performance for AI training and 1 exaflop for HPC applications, while consuming only 18.2 megawatts of power.
Chart of deployed performance of supercomputers using NVIDIA GPUs through 2024
Research centers are poised to switch on a tsunami of GH200 performance.
Based on Eviden’s BullSequana XH3000 liquid-cooled system, JUPITER will use the NVIDIA quad GH200 system architecture and NVIDIA Quantum-2 InfiniBand networking for climate and weather predictions, drug discovery, hybrid quantum computing and digital twins. JUPITER quad GH200 nodes will be configured with 864GB of high-speed memory.
It’s one of several new supercomputers using Grace Hopper that NVIDIA announced at SC23.
The HPE Cray EX2500 system from Hewlett Packard Enterprise will use the quad GH200 to power many AI supercomputers coming online next year.
For example, HPE uses the quad GH200 to power OFP-II, an advanced HPC system in Japan shared by the University of Tsukuba and the University of Tokyo, as well as the DeltaAI system, which will triple computing capacity for the U.S. National Center for Supercomputing Applications.
HPE is also building the Venado system for the Los Alamos National Laboratory, the first GH200 to be deployed in the U.S. In addition, HPE is building GH200 supercomputers in the Middle East, Switzerland and the U.K.
Grace Hopper in Texas and Beyond
At the Texas Advanced Computing Center (TACC), Dell Technologies is building the Vista supercomputer with NVIDIA Grace Hopper and Grace CPU Superchips.
More than 100 global enterprises and organizations, including NASA Ames Research Center and Total Energies, have already purchased Grace Hopper early-access systems, Buck said.
They join previously announced GH200 users such as SoftBank and the University of Bristol, as well as the massive Leonardo system with 14,000 NVIDIA A100 GPUs that delivers 10 exaflops of AI performance for Italy’s Cineca consortium.
The View From Supercomputing Centers
Leaders from supercomputing centers around the world shared their plans and work in progress with the latest systems.
“We’ve been collaborating with MeteoSwiss ECMWP as well as scientists from ETH EXCLAIM and NVIDIA’s Earth-2 project to create an infrastructure that will push the envelope in all dimensions of big data analytics and extreme scale computing,” said Thomas Schultess, director of the Swiss National Supercomputing Centre of work on the Alps supercomputer.
“There’s really impressive energy-efficiency gains across our stacks,” Dan Stanzione, executive director of TACC, said of Vista.
It’s “really the stepping stone to move users from the kinds of systems we’ve done in the past to looking at this new Grace Arm CPU and Hopper GPU tightly coupled combination and … we’re looking to scale out by probably a factor of 10 or 15 from what we are deploying with Vista when we deploy Horizon in a couple years,” he said.
Accelerating the Quantum Journey
Researchers are also using today’s accelerated systems to pioneer a path to tomorrow’s supercomputers.
In Germany, JUPITER “will revolutionize scientific research across climate, materials, drug discovery and quantum computing,” said Kristel Michelson, who leads Julich’s research group on quantum information processing.
Share
NVIDIA today unveiled at SC23 the next wave of technologies that will lift scientific and industrial research centers worldwide to new levels of performance and energy efficiency.
“NVIDIA hardware and software innovations are creating a new class of AI supercomputers,” said Ian Buck, vice president of the company’s high performance computing and hyperscale data center business, in a special address at the conference.
Some of the systems will pack memory-enhanced NVIDIA Hopper accelerators, others a new NVIDIA Grace Hopper systems architecture. All will use the expanded parallelism to run a full stack of accelerated software for generative AI, HPC and hybrid quantum computing.
Buck described the new NVIDIA HGX H200 as “the world’s leading AI computing platform.”
Image of H200 GPU system
NVIDIA H200 Tensor Core GPUs pack HBM3e memory to run growing generative AI models.
It packs up to 141GB of HBM3e, the first AI accelerator to use the ultrafast technology. Running models like GPT-3, NVIDIA H200 Tensor Core GPUs provide an 18x performance increase over prior-generation accelerators.
Among other generative AI benchmarks, they zip through 12,000 tokens per second on a Llama2-13B large language model (LLM).
Buck also revealed a server platform that links four NVIDIA GH200 Grace Hopper Superchips on an NVIDIA NVLink interconnect. The quad configuration puts in a single compute node a whopping 288 Arm Neoverse cores and 16 petaflops of AI performance with up to 2.3 terabytes of high-speed memory.
Image of quad GH200 server node
Server nodes based on the four GH200 Superchips will deliver 16 petaflops of AI performance.
Demonstrating its efficiency, one GH200 Superchip using the NVIDIA TensorRT-LLM open-source library is 100x faster than a dual-socket x86 CPU system and nearly 2x more energy efficient than an X86 + H100 GPU server.
“Accelerated computing is sustainable computing,” Buck said. “By harnessing the power of accelerated computing and generative AI, together we can drive innovation across industries while reducing our impact on the environment.”
NVIDIA Powers 38 of 49 New TOP500 Systems
The latest TOP500 list of the world’s fastest supercomputers reflects the shift toward accelerated, energy-efficient supercomputing.
Thanks to new systems powered by NVIDIA H100 Tensor Core GPUs, NVIDIA now delivers more than 2.5 exaflops of HPC performance across these world-leading systems, up from 1.6 exaflops in the May rankings. NVIDIA’s contribution on the top 10 alone reaches nearly an exaflop of HPC and 72 exaflops of AI performance.
The new list contains the highest number of systems ever using NVIDIA technologies, 379 vs. 372 in May, including 38 of 49 new supercomputers on the list.
Microsoft Azure leads the newcomers with its Eagle system using H100 GPUs in NDv5 instances to hit No. 3 with 561 petaflops. Mare Nostrum5 in Barcelona ranked No. 8, and NVIDIA Eos — which recently set new AI training records on the MLPerf benchmarks — came in at No. 9.
Showing their energy efficiency, NVIDIA GPUs power 23 of the top 30 systems on the Green500. And they retained the No. 1 spot with the H100 GPU-based Henri system, which delivers 65.09 gigaflops per watt for the Flatiron Institute in New York.
Gen AI Explores COVID
Showing what’s possible, the Argonne National Laboratory used NVIDIA BioNeMo, a generative AI platform for biomolecular LLMs, to develop GenSLMs, a model that can generate gene sequences that closely resemble real-world variants of the coronavirus. Using NVIDIA GPUs and data from 1.5 million COVID genome sequences, it can also rapidly identify new virus variants.
The work won the Gordon Bell special prize last year and was trained on supercomputers, including Argonne’s Polaris system, the U.S. Department of Energy’s Perlmutter and NVIDIA’s Selene.
It’s “just the tip of the iceberg — the future is brimming with possibilities, as generative AI continues to redefine the landscape of scientific exploration,” said Kimberly Powell, vice president of healthcare at NVIDIA, in the special address.
Saving Time, Money and Energy
Using the latest technologies, accelerated workloads can see an order-of-magnitude reduction in system cost and energy used, Buck said.
For example, Siemens teamed with Mercedes to analyze aerodynamics and related acoustics for its new electric EQE vehicles. The simulations that took weeks on CPU clusters ran significantly faster using the latest NVIDIA H100 GPUs. In addition, Hopper GPUs let them reduce costs by 3x and reduce energy consumption by 4x (below).
Chart showing the performance and energy efficiency of H100 GPUs
Switching on 200 Exaflops Beginning Next Year
Scientific and industrial advances will come from every corner of the globe where the latest systems are being deployed.
“We already see a combined 200 exaflops of AI on Grace Hopper supercomputers going to production 2024,” Buck said.
They include the massive JUPITER supercomputer at Germany’s Jülich center. It can deliver 93 exaflops of performance for AI training and 1 exaflop for HPC applications, while consuming only 18.2 megawatts of power.
Chart of deployed performance of supercomputers using NVIDIA GPUs through 2024
Research centers are poised to switch on a tsunami of GH200 performance.
Based on Eviden’s BullSequana XH3000 liquid-cooled system, JUPITER will use the NVIDIA quad GH200 system architecture and NVIDIA Quantum-2 InfiniBand networking for climate and weather predictions, drug discovery, hybrid quantum computing and digital twins. JUPITER quad GH200 nodes will be configured with 864GB of high-speed memory.
It’s one of several new supercomputers using Grace Hopper that NVIDIA announced at SC23.
The HPE Cray EX2500 system from Hewlett Packard Enterprise will use the quad GH200 to power many AI supercomputers coming online next year.
For example, HPE uses the quad GH200 to power OFP-II, an advanced HPC system in Japan shared by the University of Tsukuba and the University of Tokyo, as well as the DeltaAI system, which will triple computing capacity for the U.S. National Center for Supercomputing Applications.
HPE is also building the Venado system for the Los Alamos National Laboratory, the first GH200 to be deployed in the U.S. In addition, HPE is building GH200 supercomputers in the Middle East, Switzerland and the U.K.
Grace Hopper in Texas and Beyond
At the Texas Advanced Computing Center (TACC), Dell Technologies is building the Vista supercomputer with NVIDIA Grace Hopper and Grace CPU Superchips.
More than 100 global enterprises and organizations, including NASA Ames Research Center and Total Energies, have already purchased Grace Hopper early-access systems, Buck said.
They join previously announced GH200 users such as SoftBank and the University of Bristol, as well as the massive Leonardo system with 14,000 NVIDIA A100 GPUs that delivers 10 exaflops of AI performance for Italy’s Cineca consortium.
The View From Supercomputing Centers
Leaders from supercomputing centers around the world shared their plans and work in progress with the latest systems.
“We’ve been collaborating with MeteoSwiss ECMWP as well as scientists from ETH EXCLAIM and NVIDIA’s Earth-2 project to create an infrastructure that will push the envelope in all dimensions of big data analytics and extreme scale computing,” said Thomas Schultess, director of the Swiss National Supercomputing Centre of work on the Alps supercomputer.
“There’s really impressive energy-efficiency gains across our stacks,” Dan Stanzione, executive director of TACC, said of Vista.
It’s “really the stepping stone to move users from the kinds of systems we’ve done in the past to looking at this new Grace Arm CPU and Hopper GPU tightly coupled combination and … we’re looking to scale out by probably a factor of 10 or 15 from what we are deploying with Vista when we deploy Horizon in a couple years,” he said.
Accelerating the Quantum Journey
Researchers are also using today’s accelerated systems to pioneer a path to tomorrow’s supercomputers.
In Germany, JUPITER “will revolutionize scientific research across climate, materials, drug discovery and quantum computing,” said Kristel Michelson, who leads Julich’s research group on quantum information processing.
“JUPITER’s architecture also allows for the seamless integration of quantum algorithms with parallel HPC algorithms, and this is mandatory for effective quantum HPC hybrid simulations,” she said.
CUDA Quantum Drives Progress
The special address also showed how NVIDIA CUDA Quantum — a platform for programming CPUs, GPUs and quantum computers also known as QPUs — is advancing research in quantum computing.
For example, researchers at BASF, the world’s largest chemical company, pioneered a new hybrid quantum-classical method for simulating chemicals that can shield humans against harmful metals. They join researchers at Brookhaven National Laboratory and HPE who are separately pushing the frontiers of science with CUDA Quantum.
NVIDIA also announced a collaboration with Classiq, a developer of quantum programming tools, to create a life sciences research center at the Tel Aviv Sourasky Medical Center, Israel’s largest teaching hospital. The center will use Classiq’s software and CUDA Quantum running on an NVIDIA DGX H100 system.
Separately, Quantum Machines will deploy the first NVIDIA DGX Quantum, a system using Grace Hopper Superchips, at the Israel National Quantum Center that aims to drive advances across scientific fields. The DGX system will be connected to a superconducting QPU by Quantware and a photonic QPU from ORCA Computing, both powered by CUDA Quantum.
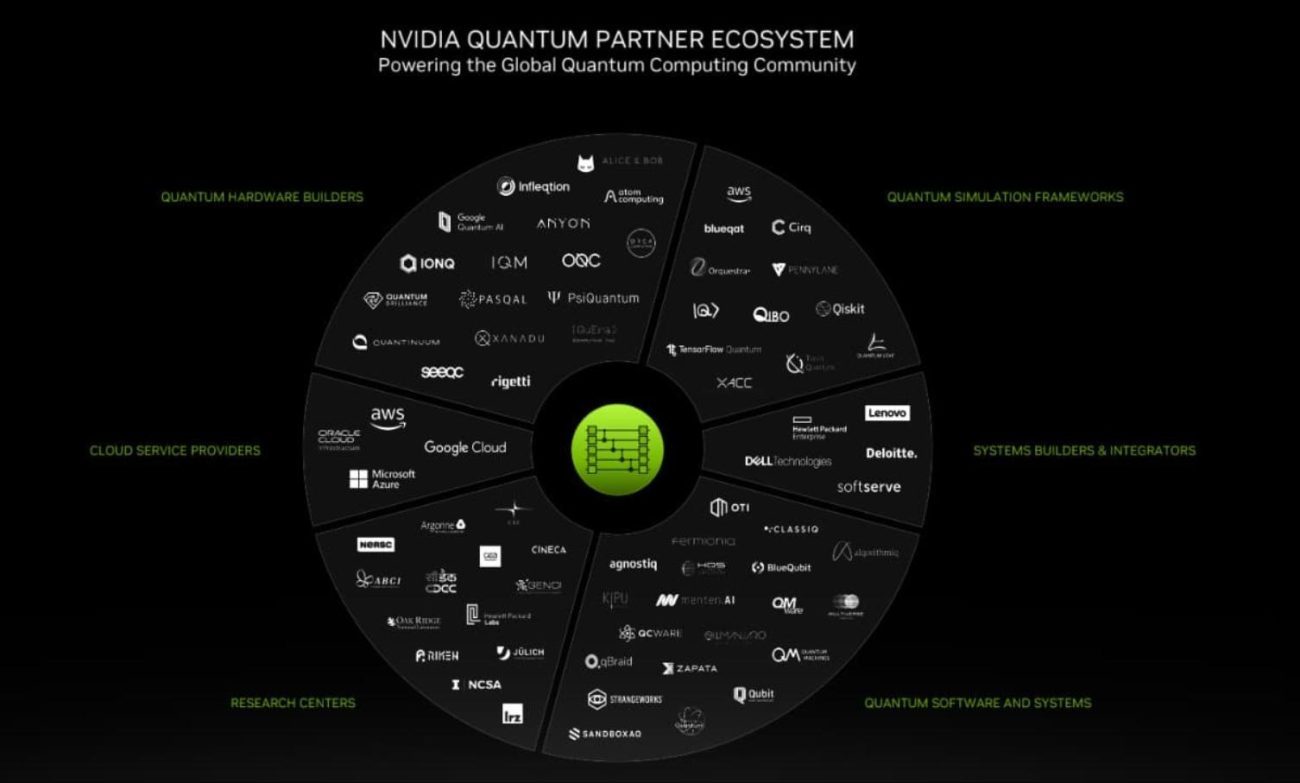
“In just two years, our NVIDIA quantum computing platform has amassed over 120 partners [above], a testament to its open, innovative platform,” Buck said.
Overall, the work across many fields of discovery reveals a new trend that combines accelerated computing at data center scale with NVIDIA’s full-stack innovation.
“Accelerated computing is paving the path for sustainable computing with advancements that provide not just amazing technology but a more sustainable and impactful future,” he concluded.
老黄深夜炸场,世界最强AI芯片H200震撼发布!性能飙升90%,Llama 2推理速度翻倍,大批超算中心来袭
刚刚,英伟达发布了目前世界最强的AI芯片H200,性能较H100提升了60%到90%,还能和H100兼容。算力荒下,大科技公司们又要开始疯狂囤货了。

英伟达的节奏,越来越可怕了。
就在刚刚,老黄又一次在深夜炸场——发布目前世界最强的AI芯片H200!
较前任霸主H100,H200的性能直接提升了60%到90%。
不仅如此,这两款芯片还是互相兼容的。这意味着,使用H100训练/推理模型的企业,可以无缝更换成最新的H200。
全世界的AI公司都陷入算力荒,英伟达的GPU已经千金难求。英伟达此前也表示,两年一发布的架构节奏将转变为一年一发布。
就在英伟达宣布这一消息之际,AI公司们正为寻找更多H100而焦头烂额。
英伟达的高端芯片价值连城,已经成为贷款的抵押品。
至于H200系统,英伟达表示预计将于明年二季度上市。
同在明年,英伟达还会发布基于Blackwell架构的B100,并计划在2024年将H100的产量增加两倍,目标是生产200多万块H100。
而在发布会上,英伟达甚至全程没有提任何竞争对手,只是不断强调「英伟达的AI超级计算平台,能够更快地解决世界上一些最重要的挑战。」
随着生成式AI的大爆炸,需求只会更大,而且,这还没算上H200呢。赢麻了,老黄真的赢麻了!
141GB超大显存,性能直接翻倍!
H200,将为全球领先的AI计算平台增添动力。
它基于Hopper架构,配备英伟达H200 Tensor Core GPU和先进的显存,因此可以为生成式AI和高性能计算工作负载处理海量数据。
英伟达H200是首款采用HBM3e的GPU,拥有高达141GB的显存。

与A100相比,H200的容量几乎翻了一番,带宽也增加了2.4倍。与H100相比,H200的带宽则从3.35TB/s增加到了4.8TB/s。
英伟达大规模与高性能计算副总裁Ian Buck表示——
要利用生成式人工智能和高性能计算应用创造智能,必须使用大型、快速的GPU显存,来高速高效地处理海量数据。借助H200,业界领先的端到端人工智能超算平台的速度会变得更快,一些世界上最重要的挑战,都可以被解决。
Llama 2推理速度提升近100%
跟前代架构相比,Hopper架构已经实现了前所未有的性能飞跃,而H100持续的升级,和TensorRT-LLM强大的开源库,都在不断提高性能标准。
H200的发布,让性能飞跃又升了一级,直接让Llama2 70B模型的推理速度比H100提高近一倍!
H200基于与H100相同的Hopper架构。这就意味着,除了新的显存功能外,H200还具有与H100相同的功能,例如Transformer Engine,它可以加速基于Transformer架构的LLM和其他深度学习模型。

HGX H200采用英伟达NVLink和NVSwitch高速互连技术,8路HGX H200可提供超过32 Petaflops的FP8深度学习计算能力和1.1TB的超高显存带宽。
当用H200代替H100,与英伟达Grace CPU搭配使用时,就组成了性能更加强劲的GH200 Grace Hopper超级芯片——专为大型HPC和AI应用而设计的计算模块。
HGX H200采用英伟达NVLink和NVSwitch高速互连技术,8路HGX H200可提供超过32 Petaflops的FP8深度学习计算能力和1.1TB的超高显存带宽。
当用H200代替H100,与英伟达Grace CPU搭配使用时,就组成了性能更加强劲的GH200 Grace Hopper超级芯片——专为大型HPC和AI应用而设计的计算模块。
因为计算核心更新幅度不大,如果以训练175B大小的GPT-3为例,性能提升大概在10%左右。
显存带宽对于高性能计算(HPC)应用程序至关重要,因为它可以实现更快的数据传输,减少复杂任务的处理瓶颈。
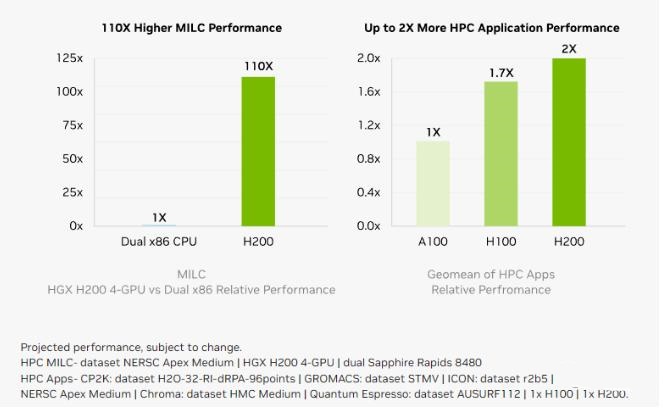
对于模拟、科学研究和人工智能等显存密集型HPC应用,H200更高的显存带宽可确保高效地访问和操作数据,与CPU相比,获得结果的时间最多可加快110倍。
相较于H100,H200在处理高性能计算的应用程序上也有20%以上的提升。
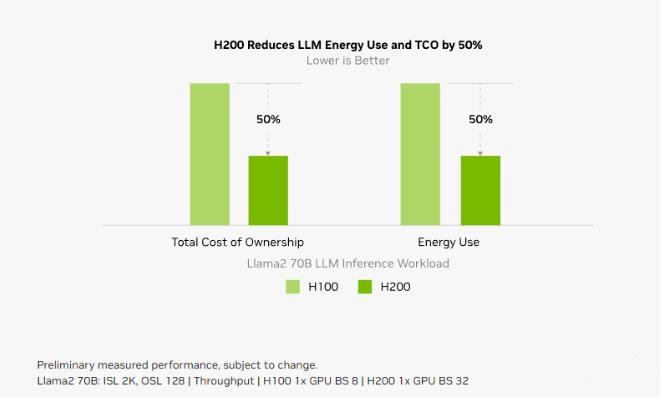
而对于用户来说非常重要的推理能耗,H200相比H100直接腰斩。
这样,H200能大幅降低用户的使用成本,继续让用户「买的越多,省的越多」!
上个月,外媒SemiAnalysis曾曝出一份英伟达未来几年的硬件路线图,包括万众瞩目的H200、B100和「X100」GPU。
而英伟达官方,也公布了官方的产品路线图,将使用同一构架设计三款芯片,在明年和后年会继续推出B100和X100。
B100,性能已经望不到头了
这次,英伟达更是在官方公告中宣布了全新的H200和B100,将过去数据中心芯片两年一更新的速率直接翻倍。
以推理1750亿参数的GPT-3为例,今年刚发布的H100是前代A100性能的11倍,明年即将上市的H200相对于H100则有超过60%的提升,而再之后的B100,性能更是望不到头。
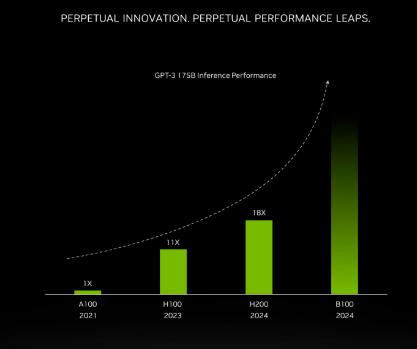
至此,H100也成为了目前在位最短的「旗舰级」GPU。
如果说H100现在就是科技行业的「黄金」,那么英伟达又成功制造了「铂金」和「钻石」。

H200加持,新一代AI超算中心大批来袭
云服务方面,除了英伟达自己投资的CoreWeave、Lambda和Vultr之外,亚马逊云科技、谷歌云、微软Azure和甲骨文云基础设施,都将成为首批部署基于H200实例的供应商。
此外,在新的H200加持之下,GH200超级芯片也将为全球各地的超级计算中心提供总计约200 Exaflops的AI算力,用以推动科学创新。
在SC23大会上,多家顶级超算中心纷纷宣布,即将使用GH200系统构建自己的超级计算机。
德国尤里希超级计算中心将在超算JUPITER中使用GH200超级芯片。
这台超级计算机将成为欧洲第一台超大规模超级计算机,是欧洲高性能计算联合项目(EuroHPC Joint Undertaking)的一部分。
Jupiter超级计算机基于Eviden的BullSequana XH3000,采用全液冷架构。
它总共拥有24000个英伟达GH200 Grace Hopper超级芯片,通过Quantum-2 Infiniband互联。
每个Grace CPU包含288个Neoverse内核, Jupiter的CPU就有近700万个ARM核心。
它能提供93 Exaflops的低精度AI算力和1 Exaflop的高精度(FP64)算力。这台超级计算机预计将于2024年安装完毕。
由筑波大学和东京大学共同成立的日本先进高性能计算联合中心,将在下一代超级计算机中采用英伟达GH200 Grace Hopper超级芯片构建。
作为世界最大超算中心之一的德克萨斯高级计算中心,也将采用英伟达的GH200构建超级计算机Vista。

伊利诺伊大学香槟分校的美国国家超级计算应用中心,将利用英伟达GH200超级芯片来构建他们的超算DeltaAI,把AI计算能力提高两倍。
此外,布里斯托大学将在英国政府的资助下,负责建造英国最强大的超级计算机Isambard-AI——将配备5000多颗英伟达GH200超级芯片,提供21 Exaflops的AI计算能力。
英伟达、AMD、英特尔:三巨头决战AI芯片
GPU竞赛,也进入了白热化。

面对H200,而老对手AMD的计划是,利用即将推出的大杀器——Instinct MI300X来提升显存性能。
MI300X将配备192GB的HBM3和5.2TB/s的显存带宽,这将使其在容量和带宽上远超H200。
而英特尔也摩拳擦掌,计划提升Gaudi AI芯片的HBM容量,并表示明年推出的第三代Gaudi AI芯片将从上一代的 96GB HBM2e增加到144GB。
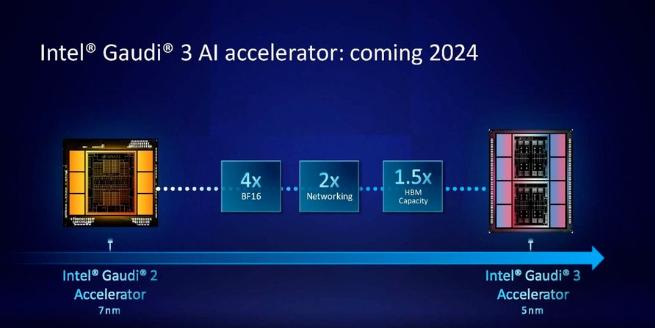
英特尔Max系列目前的HBM2容量最高为128GB,英特尔计划在未来几代产品中,还要增加Max系列芯片的容量。
H200价格未知
所以,H200卖多少钱?英伟达暂时还未公布。
要知道,一块H100的售价,在25000美元到40000美元之间。训练AI模型,至少需要数千块。
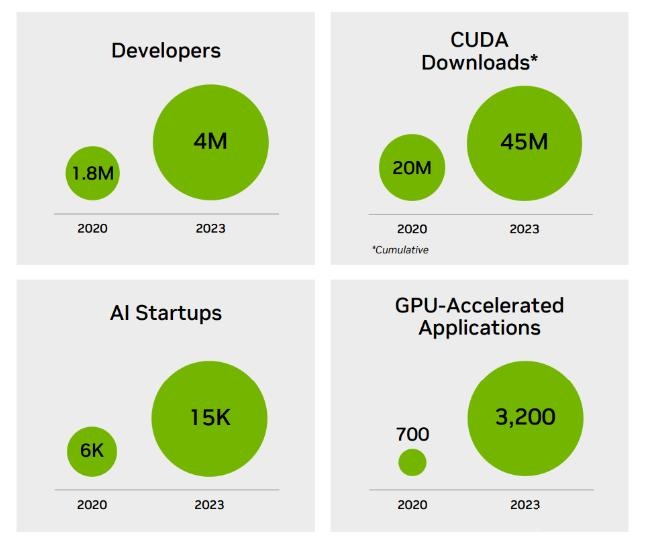
此前,AI社区曾广为流传这张图片《我们需要多少个GPU》。

GPT-4大约是在10000-25000块A100上训练的;Meta需要大约21000块A100;Stability AI用了大概5000块A100;Falcon-40B的训练,用了384块A100。
根据马斯克的说法,GPT-5可能需要30000-50000块H100。摩根士丹利的说法是25000个GPU。
Sam Altman否认了在训练GPT-5,但却提过「OpenAI的GPU严重短缺,使用我们产品的人越少越好」。
我们能知道的是,等到明年第二季度H200上市,届时必将引发新的风暴。